
Digital Product Passport in 2024: Lessons for 2027

Back in mid-2024, I spent four months at Deloitte building a Digital Product Passport (DPP) proof-of-concept for batteries in two-wheeled electric vehicles. E-bikes, e-scooters, light EVs. At the time, the EU’s Ecodesign for Sustainable Products Regulation had just entered into force, the Battery Regulation 2023/1542 was less than a year old, and almost nobody outside policy circles had a clear picture of what a real DPP implementation looked like.
Two years on, things look very different. The EU Central DPP Registry goes live on 19 July 2026. The Battery Passport mandate kicks in on 18 February 2027. What used to be a policy discussion is now a shipping deadline.
So this post is a look back. What we built, what held up, and what I’d undo if I were starting today.
The code is open-source: github.com/0xNadr/xdc-hardhat-dpp.
The problem nobody puts on the slide deck
Most introductions to DPPs describe them as “a QR code that links to product data.” True. Useless.
The interesting problem isn’t the QR code. It’s the data model behind it.
A real DPP for a battery has to satisfy four things at the same time:
- Regulator-grade transparency. Material composition, carbon footprint, recycled content, due diligence on the supply chain.
- Supplier confidentiality. Your tier-2 cobalt supplier’s location, contract terms, and process parameters are competitive intelligence, not public information.
- Cross-organizational write access. The manufacturer writes assembly data. The supplier writes material data. The recycler writes end-of-life data. The repair shop writes service history.
- Persistence beyond any single company. The passport has to survive the manufacturer going bust, getting acquired, or just losing interest after the warranty expires.
Once you write those four down, two things become obvious. First, a single database owned by the manufacturer is not enough. Second, “put it all on a blockchain” is also not the answer. Most of the data is too sensitive to publish, and most of the actors don’t want their writes to be globally visible.
That tension is the actual engineering problem. Privacy versus transparency. Controlled access versus open auditability. Everything else is plumbing.
What we built: a dual-contract architecture on XDC
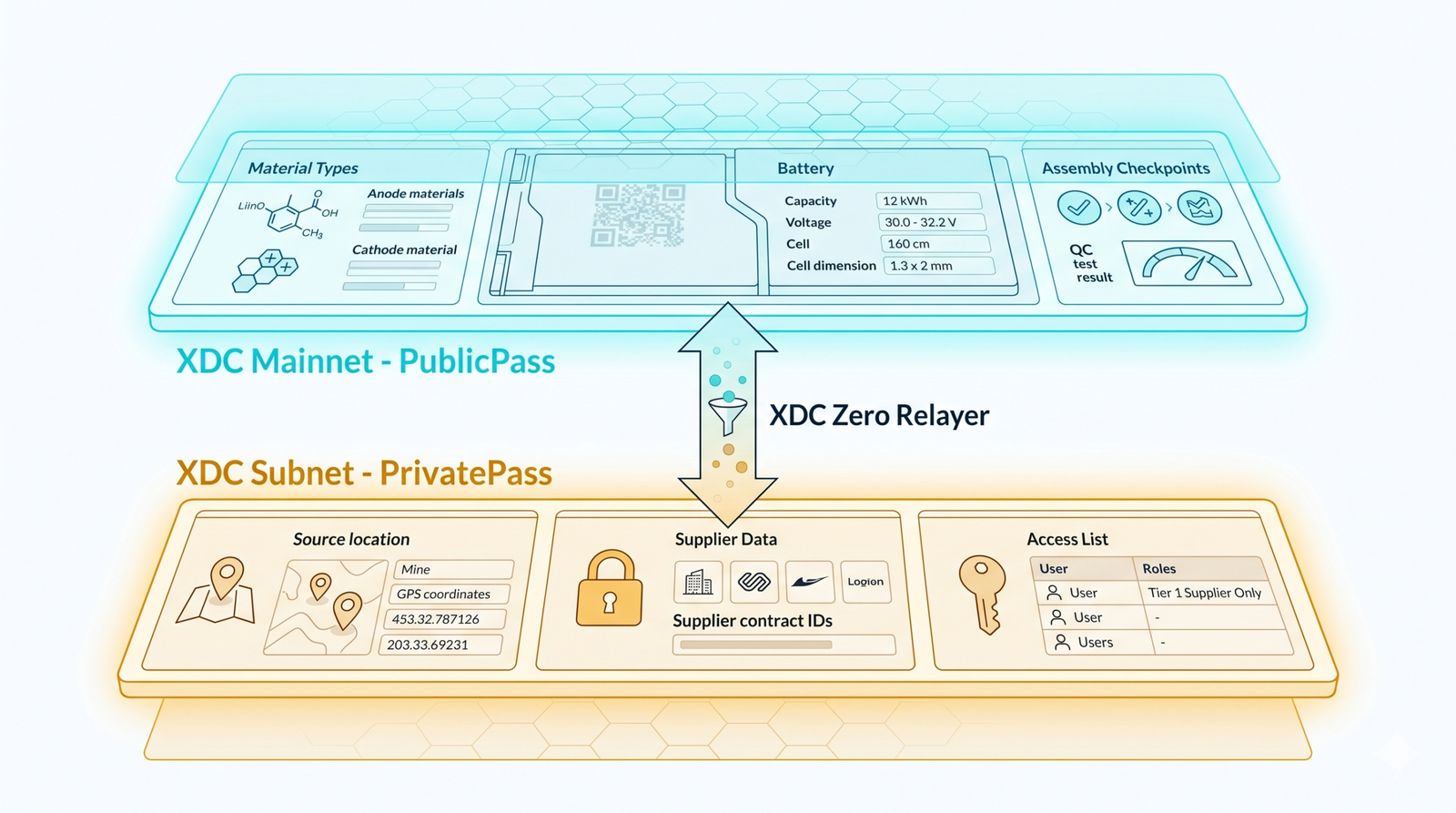
The approach was to split the passport across two smart contracts on two different layers of the XDC Network.
PublicPass lived on XDC mainnet. It held the non-sensitive data: material types (not sources), battery specifications, assembly checkpoints. Anyone could read it. Ownership controls governed who could write.
PrivatePass lived on a private XDC subnet. It held the sensitive data: source locations, extraction dates, supplier-specific technical parameters. Access was controlled by an explicit accessList. Only addresses on the list could read individual entries. The contract owner could grant or revoke access with grantAccess and revokeAccess, and every change was emitted as a logged event for audit.
The two layers connected through XDC Zero Relayer, which let us selectively bridge information from the private subnet to the public mainnet. That’s where the design got interesting.
The aggregation pattern
The hardest design question was this: how do you give regulators and consumers useful information without leaking the underlying supplier data?
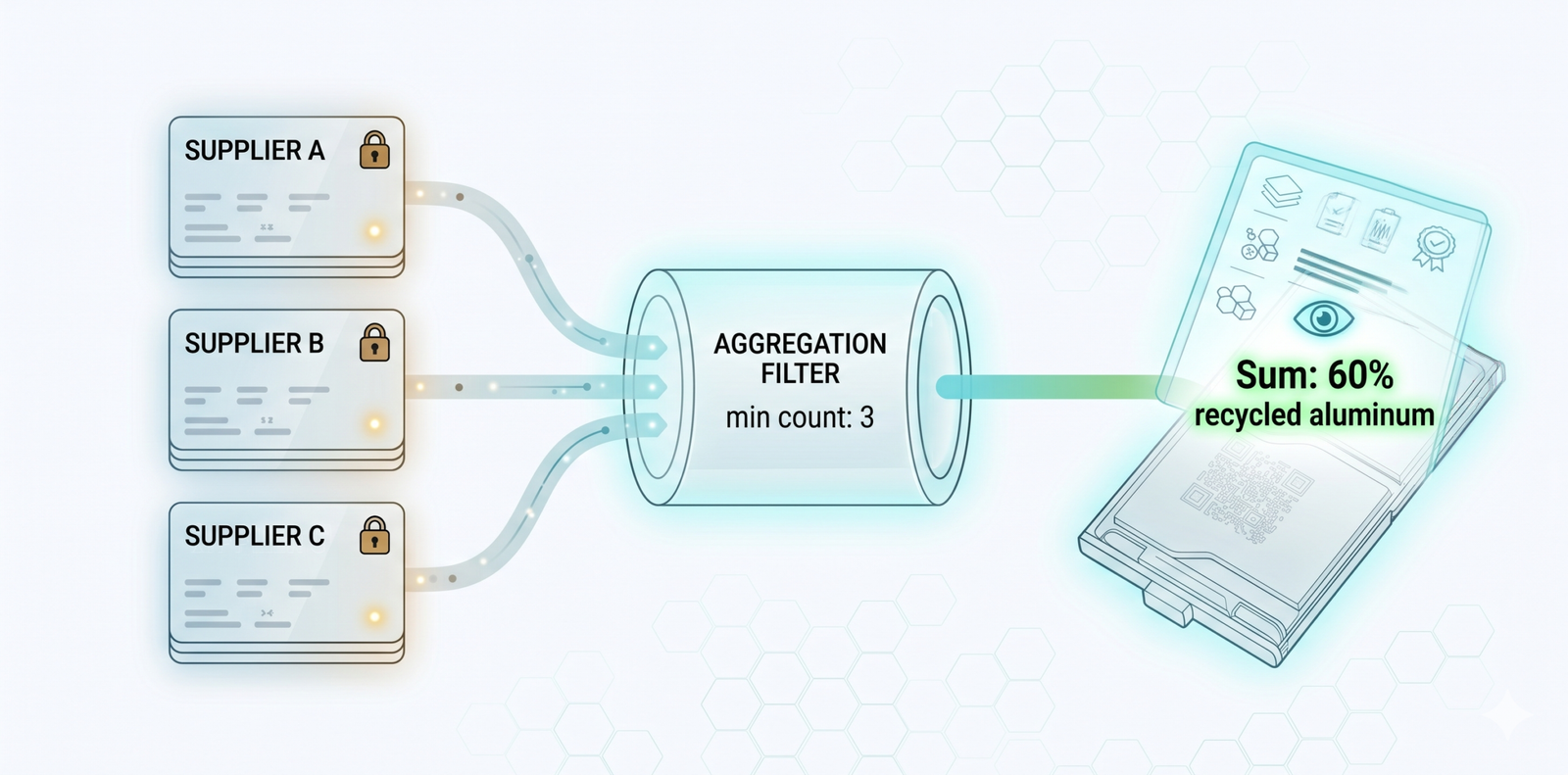
The answer we landed on was aggregation with a minimum-count threshold.
The PrivatePass contract stored individual records, but it also maintained running sums and counts for each numeric key. getAggregateData would return those summaries, but only when the count of underlying data points met a minimum threshold. We used 3 as a default.
If a manufacturer wanted to publish “total recycled aluminum content across all batches in Q3,” that aggregate could be computed from the private records and emitted as a public event, ready to be relayed to mainnet. If only one supplier had contributed data, the aggregate would refuse to return. No leakage of any single supplier’s contribution.
It’s a primitive version of k-anonymity, baked into the contract. Not bulletproof. A motivated adversary could correlate timing and re-identify. But it’s adequate for a PoC, and an honest attempt at privacy-by-design.
The pattern generalizes well beyond batteries. Anywhere you want “show me the supply chain metrics without exposing the suppliers” (textile mills, electronics components, food provenance), the same mechanic applies.
What held up
The public/private split was the right instinct. Two years on, the major DPP architecture proposals (CIRPASS-2, GS1’s recommendations, the EU’s own service-provider rules) all converge on some version of layered data with differentiated access. The specifics differ. The principle is shared.
Access control as an explicit, audit-logged list was right. Every serious DPP implementation will need this. Regulators will demand it. GDPR effectively requires it for any data that touches a person.
Aggregation as a first-class operation was right. The market figured out in 2025 and 2026 that DPP data has to be queryable in summary without being readable in detail. Most platforms bolt this on as a reporting layer. Building it into the storage layer is cleaner.
What I’d change
Blockchain was the wrong default for most of the data.
We chose XDC because the project was framed as a blockchain PoC. That was the brief. With hindsight, the only data that genuinely benefits from on-chain storage is the identifier and its provenance proof. The actual passport payload should live in standard, queryable databases owned by accountable parties, with cryptographic anchoring to a public ledger only where tamper-evidence is genuinely required. A federated permissioned data architecture with verifiable credentials would have been simpler, cheaper, and easier to scale.
We invented our own identifier scheme.
In 2024 the standards landscape wasn’t yet settled. In 2026 it is. The EU is converging on GS1 Digital Link as the URL structure for DPP access (/01/{GTIN}/10/{lot}/21/{serial}). Battery passports specifically will use this format. If I were starting again, the entire identifier and resolver layer would be GS1-conformant from day one, with the contracts mapping to those identifiers rather than defining their own.
We didn’t use EPCIS for events.
GS1’s EPCIS 2.0 is the de facto event standard for supply-chain lifecycle data. Manufacture, ship, receive, transform, sell, repair, recycle. Our contract’s custom event emissions did the same job, badly. EPCIS gives you a vocabulary that already maps onto regulatory reporting categories. There’s no good reason to roll your own.
Trust attestations should be W3C Verifiable Credentials.
When a supplier writes “this aluminum is 60% recycled,” that statement needs to be cryptographically attestable, revocable, and verifiable independently of the platform hosting it. The W3C VC Data Model is purpose-built for this. We treated it as an access-control problem. It’s really a credentialing problem.
Cross-chain via a relayer added more complexity than it removed.
Bridging aggregates from the subnet to mainnet was elegant in theory and fragile in practice. Every cross-chain hop introduces a trust assumption and an operational dependency. A simpler model: keep private data in a permissioned store, sign cross-references with the operator’s key, and anchor proofs (not data) to a public chain at intervals.
The hard problems aren’t blockchain problems
The most important thing I learned in those four months had nothing to do with smart contracts.
The hard part of DPP is the federated data model.
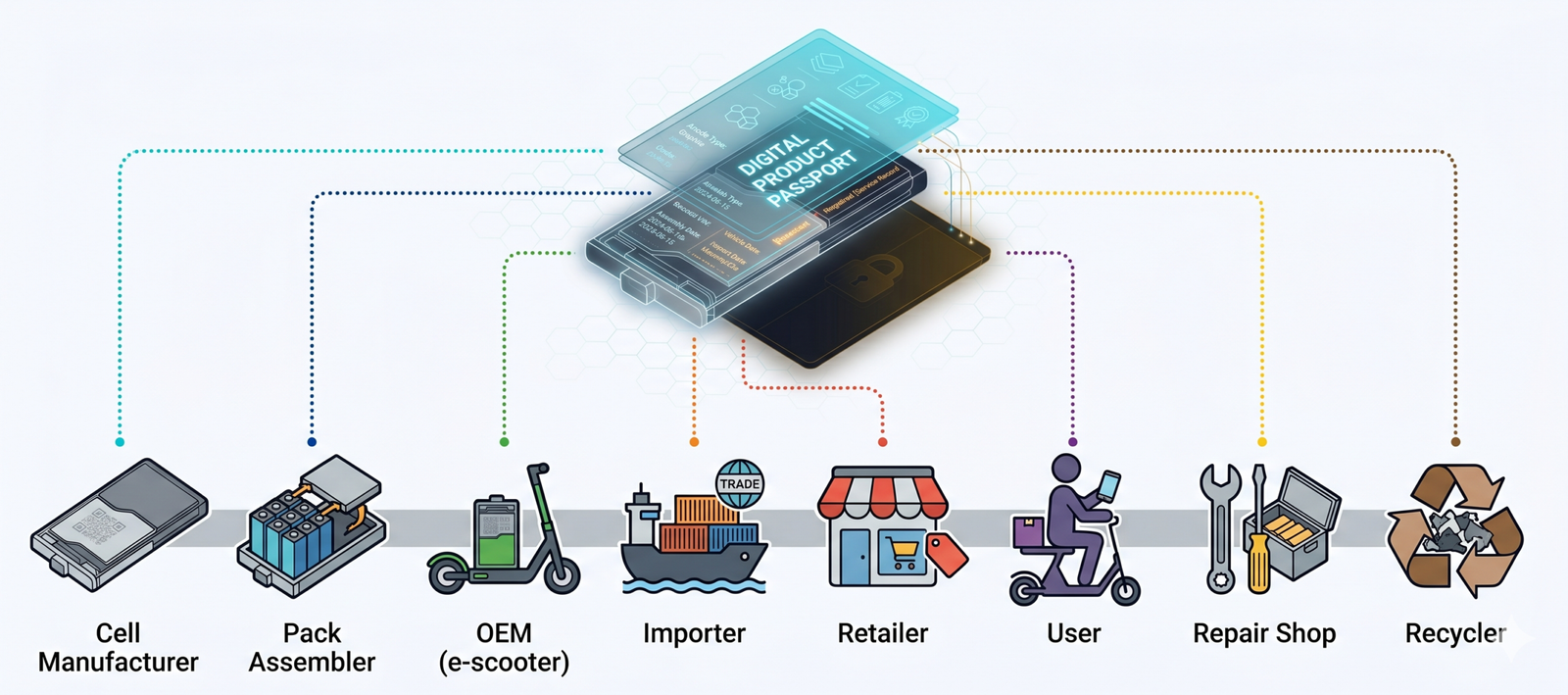
A single battery’s passport will collect contributions from a dozen entities. The cell manufacturer. The pack assembler. The OEM that integrates it into a scooter. The importer that brings the scooter into the EU. The retailer that sells it. The repair shop that replaces a module. The recycler that processes it at end-of-life. Each of these actors has different write rights, different motivations, different IT maturity, and different reasons to lie.
Designing a system that lets all of them contribute trustworthy data to the same passport, without giving any one of them unilateral control, and without requiring all of them to use the same software, is the actual problem. Blockchain is one possible substrate for solving it. So is a permissioned trust network with verifiable credentials. So is a centralized platform operated by a trusted third party with strong governance.
The architectural debate that occupied 2022 to 2024 (blockchain vs. centralized database) is mostly over. The debate that defines 2026 and 2027 is centralized service provider vs. federated trust network. EON, Circulor, Circularise, Spherity, Authena are all betting different answers to that question. Watching how it resolves is the most interesting thing happening in this corner of supply-chain tech.
Why I’m posting this now
Two reasons.
First, the implementation window is closing. From this summer, every EV and industrial battery sold into the EU needs a Battery Passport. The next 18 months will see more DPP code shipped to production than the previous five years combined. Most of the people writing that code are doing it for the first time. If anything in this post saves someone a wrong turn I took, that’s worth writing.
Second, I’m spending more of my time on this space. The intersection of regulated data infrastructure, supply chain, and circular commerce. If you’re building in this area, or you’re at a company that needs to be ready for the 2027 to 2030 wave, say hello. I’d like to compare notes.
The code from the 2024 work is here: github.com/0xNadr/xdc-hardhat-dpp. It’s a snapshot, not a maintained reference. The design choices it embodies are partly right and partly outdated, in the ways above. Read it as a record of what the field looked like in mid-2024, not as a blueprint for mid-2026.
The next post will be a sketch of what I’d actually build today. GS1 Digital Link as the identifier. Verifiable credentials as the trust layer. EPCIS as the event log. A minimal anchoring contract for tamper-evidence. If that’s the post you’d actually read, let me know and I’ll write it sooner.